It’s estimated that 95% of corporate information exists on paper and/or scanned documents. Most agreements, contracts, invoices, reports, etc. that are digitized either through scanning or creation (i.e., MS Word, Excel, etc.) are built to reflect their respective version as if they were typed on physical paper. There is so much data and information stored on printed, scanned, and fully digitized documents. Imagine for a minute, in an ideal world, a company was able to meaningfully extract every document, catalog and search for it within a few clicks? In addition, if these companies were able to create machine learning models to help with decisioning and provide a comprehensive historical analysis of everything related to the company. This productivity gain could change the way businesses work and hire. A fully digitized company with this profile is nonexistent at this point but it could be more commonplace in the next 10 years. The main obstacle has always been the reliability of the technology. As I wrote in a previous blog, it’s my belief that IDP will be one of the top use cases in 2023 and beyond.
So, what has changed with this technology that makes it so powerful now?
I think it’s worth going through a little bit of history to fully understand where we are now and how exciting it is. Optical Character Recognition (OCR) has been around since the early 1930’s when it was originally called a “Statistical Machine” for searching microfilm archives for characters. The approach has helped visually impaired people and assistive technologies to read documents. HP created a widely used approach which involved dictionaries for common phrases and words called Tesseract. Google has since adopted it as part of their approach to reading characters via documents and applications.
Today, with the use of highly sophisticated AI, OCR in the cloud, extracting text from documents is as close to 100% reliable as it has ever been before. This includes reading typed text and even handwriting (within reason).
The reading of characters and extracting words are certainly great benchmarks but only solve part of the use case most businesses have. Whether it be scanned documents or screens, traditional positional OCR is very brittle. Structure is important for many of the leading OCR engines (i.e., ABBYY, Amazon Textract and UiPath Document Understanding.)
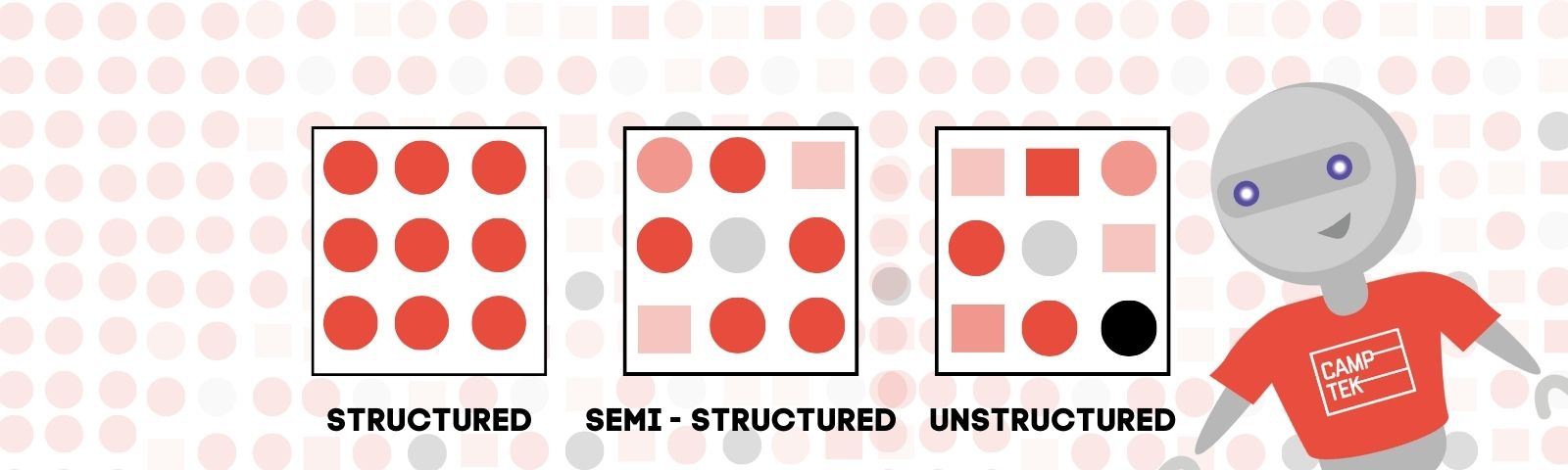
It’s important to understand the differences between Structured, Semi Structured and Unstructured Data.
Structured data is a very predictable format where there is minimal, if no variance, as to where data is located. A good example might be an intake form at a doctor’s office or customs form one has to fill out in order to enter countries. So, data values like name, date, nationality are always in the same spot and the answers are consistently next to those items. This type of scanning requires OCR and evaluating the key value pair for each answer, i.e., Name: John Smith. Name will always have the name next to it. Extraction is high positional since these items don’t move.
That can’t be said for semi structured data. While some of the data is predictable, frequently there is some variance. Invoices, receipts, and purchase orders typically fall in this category. The challenge that comes with these types of documents are the variances in each of the document types. An example could be an invoice from Staples. One could order 1 item or 100 items and the positional nature is lost because of where the end of the invoice varies from order to order. It can get even more complex when trying to process, not just Staples invoices, but all of the other companies that are sending invoices. One company may have Invoice Number as “Invoice #” another might have it as “Invoice No.”. This category of structured data is fertile with solutions from various document understanding companies and continues to improve enormously. UiPath for instance, has one of the top Document Understanding products in this very competitive space.
Finally, my favorite category of the bunch and the biggest area for opportunity in 2023 and beyond, Unstructured Data. There is essentially no predictability as to where data is located on one document to the next. Contracts, legal documents, doctors orders, handwritten documents and insurance claims all fall in this category. Since nothing is positional, the strategy is to create commonality on the type of data you are trying to extract or else trigger phrases are the way to train these type of models. Since OCR engines, at this point, are very sophisticated and can read almost anything, the challenge is to find a solution that can perform this type of task. Indico Data is the top vendor in this space at the moment.
It’s my thought that the unstructured data space is where most of the 95% of corporate information exists and where the long-term value add is. The first step will be to capture this data with close to 100% reliability and then store the data and create machine learning models out of them which can help with AI decisioning. Beyond that, having sufficient search capabilities can only provide companies with more readily available and useful data.
–Peter Camp, CTO & Founder, CampTek Software

